Not interested in explanations? Fast travel to the tl;dr 🚀
If you use Grav, you probably use Grav-specific URL parameters.
Like regular URL query parameters (/blog?key=value), they are appended to the base URL with a /key:value syntax and are then processed independently by Grav. Similarly, they can also be chained.
As an example, collections can by default be filtered based on taxonomies, as demonstrated on this blog:
/blog/tag:gravwill filter entries tagged withgrav./blog/archives_month:2020_09will filter entries written in September 2020./blog/tag:grav/archives_month:2020_09will filter entries tagged withgravand written in September 2020.
Note: collections’ taxonomy filtering can be disabled by setting url_taxonomy_filters: false in the YAML front matter.
Even better: when using the default theme (Quark), the Taxonomy List and Archives plugins allow users to filter blog entries from the sidebar with the help of Grav parameters.
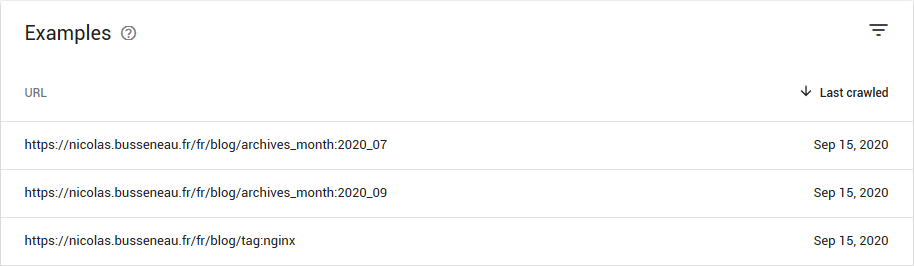
However, if included in the sidebar, they are scrapable by search engines. It seems that at least Google treats them as separate pages, even if canonical link elements and sitemaps are present:
As specified in Google’s documentation, the indexer may choose to ignore content-provided indicators:
Google chooses the canonical page based on a number of factors (or signals), such as whether the page is served via http or https; page quality; presence of the URL in a sitemap; and any “rel=canonical” labeling. You can indicate your preference to Google using these techniques, but Google may choose a different page as canonical than you do, for various reasons.
This behavior might be undesirable. In this case, the only resort is to block indexing using a noindex <meta> tag:
<meta name="robots" content="noindex">Obviously, we’d only want to block indexing for URLs with Grav parameters. Including the <meta> tag in a base template would not be suitable: it must be conditionally inserted. Fortunately, the Uri::params() function may be used to determine if Grav parameters are present. A PR is open to integrate this feature as a Quark theme toggle, but until then…
tl;dr
URLs with Grav parameters may be indexed by search engines (notably Google), which might be undesirable. Using a conditionally-inserted noindex <meta> tag allows regular pages to be indexed as usual while ignoring Grav parameters:
{% if uri.params is not empty -%}
<meta name="robots" content="noindex">
{% endif %}
